


What is an SLO? What is it suitable for?

Recently, I’ve had the opportunity to help different organisations implement service-level objectives. The experience has been great, and the organisations are much better due to these clear boundaries (at least). But through this, a familiar series of questions or challenges have come up for each organisation. Today, I want to talk you through a service level objective and what they’re suitable for. Later, I’ll also publish some guidance on how you can practically implement a service-level objective in your organisation.
The road so far
Most of my experience with service-level objectives (or “SLOs”) has been at Zalando. Zalando started with SLOs in 2016 and has been on an evolving path to try and improve their effectiveness. You can read more about that journey in an excellent article by my former colleague Pedro Alves on the Zalando Engineering Blog. The journey hasn’t been smooth, and the organisation's handling of SLOs requires patience and enablement with engineers, managers, product colleagues and executives. You can learn more about how we use these in practice by watching the SLOConf video.
This article is designed to boil down that seven years of experience into something you can practically leverage within your organisations.
The fundamental problem

When leveraged collectively, engineers can produce software that can fundamentally change the economics of a business, dramatically reducing the cost of a required business operation and opening new markets! However, engineers are some of the more expensive colleagues to hire, and the talent pool for engineers is limited. Additionally, for any given software, there’s a hard limit on how many engineers it's possible to add before the amount of work required to coordinate those engineers outweighs the additional capacity a single engineer adds.
Those of us responsible for the engineering time of ourselves and others agonise over the question:
How do I spend my engineer's time to benefit the organisation as much as possible?
Even if we have engineering time, an engineer's work is more than adding new, exciting user features to our product. They also need to ensure the software:
Continues to work as expected for users, especially when user demand changes or new features are released.
Remains secure as new vulnerabilities are discovered.
Is sufficiently clear and straightforward so that new colleagues can be onboarded and effectively contribute
It runs efficiently, so the business pays little for the underlying computing.
Different organisations need to make different tradeoffs. A startup might not care as much about reliability or cost as it does about implementing the significant new features required to onboard a new client. The question is then how to split our engineering capacity amongst these tasks. We could choose it based on recent input, managerial decision or gut feeling, but there’s a better way — through data.
Measuring what matters
To establish a framework to govern engineering time, we need to be able to measure the value we get out of different kinds of engineering work. The deciding factor for where we spend engineering time is a critical business metric — financial return on investment, reduced risk of financial loss, customer lifetime value and engagement. To switch to reliability work, we need to be able to demonstrate what our current level of reliability is, as well as what the likelihood and business cost of unavailability will be.
The best way to do this is to try and measure the availability of the customer experience as close to the customer as possible. This could be at the edge of your software system (e.g. API Gateway) if you do not own the client device app, or directly in that device if you do. Try and your measurement up into segments that are meaningful to the business. We frequently use customer operations such as “add to cart” or “place order”. Each of these measurements becomes what we call a service level indicator.
Invariably, you’ll spot periods in which your reliability drops. Take a look at what happens to other critical customer metrics both during and after these periods, and see how much you’re losing as a consequence of unreliability. Keep track of it over 60 days (for example), and write a report for management, making it clear what the cost of unavailability was and what it would have been should we have kept other levels of reliability.
Setting the target
Once you’re armed with data, the next step is to work with management to make this data actionable. There are two things that you establish here:
The Target
The first thing to do is to recommend a specific target that, based on your data, is achievable without sacrificing too much product development (or other critical deliverables) but that will positively impact the customer experience and core business metrics. This target is the actual service level objective. The hint is in the name! It’s our objective
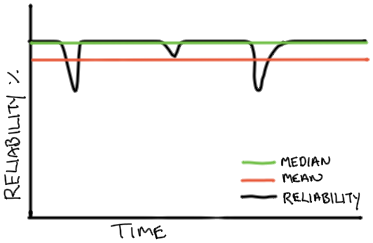
It’s often easiest to pick a number similar to the median historic availability — just be as available as you are “normally”. Suppose you’ve suffered some major issues in the meantime. In that case, there will be a difference in the median availability and the mean — the target already means that you need to spend more time on reliability work. It’s often much easier to sell management on continuing to achieve what you do on average already, and just fixing “those outliers”, and from a management perspective, it limits the maximal investment required.
An SLO is usually expressed over periods. For example:
<operation> will have an availability of 99.5% on average over 28 days.
The culture
The second and more important thing to do is to establish a routine of reviewing the service level objectives with your management or engineering planning stakeholders and using it to prioritise work to improve reliability. After all, that’s the heart of the challenge we’re looking to solve and the very purpose we designed the SLO for! It’s also the part I frequently see engineering stakeholders skip.
The error budget is the best metaphor for understanding when to prioritise reliability over other work. It is essentially “1 minus the SLO of the service”. For example, if we have an SLO of 99.5% on our operation, we say we have a “0.5%” error budget. We fully expect to spend that error budget each month! We might introduce these errors during migrations, unexpected failures, bad deployments or any other issues that carry some technical risk.
So long as we remain within that 0.5% error budget, we do not need to add more capacity to reliability work. If we exceed that 0.5% error budget, we shift our engineering allocations to prioritize reliability work until the SLO returns to where we expect.
We need our management stakeholders to agree and buy into this direction. Ultimately they are the ones who are both accountable for and drive our work, and, fundamentally, they understand the value of this approach as well as build a culture where it is respected.
Taking Action
An SLO’s error budget can be quickly exhausted by periods of complete unavailability (a “fast burn” mode) as well as an issue that “slowly leaks” unavailability (a “slow burn” mode). They need different controls to take action.
Fast Burn

For fast burn modes, the best thing to do is to set alerts on the burn rate of the error budget and forward those to an on-call team member to take action when they’re received. Google has already presented excellent work on the math of doing this efficiently; the key takeaway for this article is that you should treat it as an emergency or “incident” and prioritise fixing it above all other work.
Slow Burn
For slow burn modes, there is far less urgency to the response. A slow burn issue will mean the error budget is exhausted, but it will take many days (or even weeks!) to do so. It’s most frequently introduced due to some deployment an engineer didn’t entirely pay as much attention to as they should.
To catch these, we can either rely on the same math Google provides but with a much longer window or periodically review a projection of the SLO at the end of the period. If the SLO is projected to go outside its budget, we take action. If not, we continue with the same trade-offs we’re making now.
In Conclusion
Determining where to spend engineering time is at the heart of any modern, especially internet-based business. Service level objectives (or SLOs) are invaluable tools for helping us moderate where we spend that time clearly and objectively, moderated by the actual value of reliability for our business. We need to work hard to make sure we measure what is critical for the customer experience and, correspondingly, for the business to work rather than what is easy. We also need to work to establish the value of reliability by establishing the loss in its absence. If we do this, we can work with management to set a culture where this is prioritized and set routines both for fast and slow reliability challenges.
Or, we can get much more done with much less discussion.