
The fundamental aspects of reliability
What is it that SRE needs to care for

Editors Note: More of a visual person? That’s cool, you can watch the video version of this talk. Prefer it in writing? That’s fine too! Read on below.
One of the earliest challenges of Site Reliability Engineering (or SRE) is determining the responsibility boundary between what SRE needs to care about and what should be deferred to … someone else.
In my experience, reliability affects the following aspects of production systems:
Availability
If a system becomes “unavailable”, it cannot do what its users expect, given “reasonable” user input. Availability across different systems depends on the precise implementation of that system, but essentially, given a well-constructed input message, the desired output message does not arrive. For example,
Given a HTTP-based RPC system, the response message being a HTTP 503 “Bad Gateway” means the system is unavailable.
Given a HTTP-based RPC system, the response message being passed back after the client times out means the system is unavailable.
Given an event-based system, supplying an input event does not generate an output event across a “reasonable” time.
Measuring Availability
Usually, we measure availability as a percentage like:

We can then express that percentage over periods and set targets (or “Service Level Objectives”) on the average over those periods. For example, something like:
The service should respond with a successful message 99.9% of the time, averaging over a 28d rolling window.
Performance
The performance of a system is usually measured by assigning an “acceptable” time threshold for an operation to complete given a throughput. For example:
Given a HTTP-based RPC system, a budget of 100ms to complete the RPC
Given an event-based system, a budget of 500ms for a completion event to appear when supplied a trigger event
Systems do not generally sit on one side or another of a given performance time-bound. Rather, they approach the time bound as the throughput of operations increases until, at some point, they cannot process that throughput and the time of any given operation drifts outside that threshold.
Measuring Performance
For diagnostics purposes, it is usually better to measure performance in a histogram-like structure that puts each request into a “bucket” of performance:

The histogram distribution allows us to reason through the behaviour of a system. If a system is approaching its limit:

A bottleneck process is likely being reached, but that has not transitioned into a failure just yet — we need to scale something. Conversely, if the distribution skews:

The system is in a failure state and is unlikely to recover. Work needs to be dropped and the system scaled to allow it to recover.
More generally, to measure whether a system has an “acceptable performance”, it is simpler to measure the number of requests that are “in bound” versus those that are not — just like availability:

Correctness
A given system might be available if, given an input message, it responds with a well-formed consumable response. However, a given system can respond with a well-formed but incorrect response.
This can be very simple, such as a system designed to sum numbers supplied “2, 2” subsequently returning “5”. This is relatively straightforward to detect and should be addressed by writing sufficient test coverage around the code that reproduces the issue than fixing it.
There is also a second class of “tolerable incorrectness” in a large distributed system. Consider a system that checks all postage carriers that serve a given region to determine how long a given package would take to be delivered through that carrier:

For such a system to have a definitive answer, all of the queries to its dependencies must be successful. However, such a system is only as reliable as its least reliable dependency.
Let’s imagine that our “C” dependency is having some trouble. Our system is now unavailable:

With this design, we have failed all of our requests for delivery information just because there is a single carrier failure. This is a clearly intolerable condition! Given this, we modify our system to tolerate the failure of “C” and take the results of “A”, “B”, and “D”:
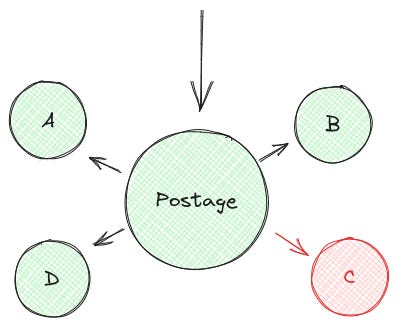
However, we now have a situation in which the request is only mostly correct.
Measuring Correctness
The only way in which I know how to measure binary correctness is to give the system an input (or a series of inputs) for which the outputs are already known, and validate the system returns those outputs when supplied those inputs. This is “end-to-end testing”, or if it is executed in production, “probes”. Measuring the correctness here is the same as availability:

Measuring mostly correct requests is more challenging. It is possible to measure the total number of requests which have any regression by marking the request with metadata indicating the regression (e.g. HTTP header), after which correctness can be measured the same way:

However, hundreds of services can contribute to a given request in a large system. At any given time, some of them are always broken. Given this, it is more useful to count the specific regressions:

This can create a large number of time series. But it can also allow weighting the regressions so that more important things (e.g. “loyalty data”) contribute more to a “quality score” than less important things (e.g. “analytics data”)
Data Recoverability
Data is a challenging issue, as there are many ways in which data can drift. However, in practice, the most critical challenge to solve is to be able to reproduce production data that will otherwise become corrupted or deleted.
There are many ways to reproduce production data, such as:
Reproduction from an event-based system
Reproduction from a state snapshot of that system, stored elsewhere.
Reconstruction of the data
Measuring Recoverability
The only way to measure the recoverability of a system is to attempt to recover it and then validate that against the production dataset. Should the data be consistent, the recovery is successful.
An organization's measurement should be time since the last successful recovery.
Machine Learning
There are a number of interesting reliability challenges associated with machine learning. Things like:
Making sure the model is trained on appropriate data and not overfit
Making sure the training data is of high quality and represents what it is designed to well
Making sure the input data is sufficiently close to the training data that the models output is still predictable
Makin sure the input data is not maliciously constructed
However, these can be considered by thinking about the machine learning model as a “black box” and then thinking about its inputs within the lens of the other reliability measures — availability, correctness, performance and data recoverability.
In Conclusion
Site Reliability Engineering is a broad discipline. However, fundamentally (at least in my experience), the problems it seeks to solve are relatively clear and consistent across multiple system archetypes.
Hopefully, this post explains them and allows you to evaluate your own SRE work against these challenges. If not, @ me to tell me I’m wrong!