
One approach to implementing Prometheus across disparate systems
As you might know, Prometheus is a time series database, designed to export time series data — things like “CPU Usage”, “Memory Usage”…

As you might know, Prometheus is a time series database, designed to export time series data — things like “CPU Usage”, “Memory Usage”, “Cron job success”. It has a number of super nice properties; it’s simple, open source (and owned by CNCF so always will be) and super widely supported.
However, this is not a post designed to sell you on Prometheus (suggest you simply try it), but rather on an approach to implementing it across your infrastructure so as to maximise it’s utility.
Prometheus is designed for something called “Federation”. It is this feature that we will use to create our infrastructure. Broadly, it looks as follows:
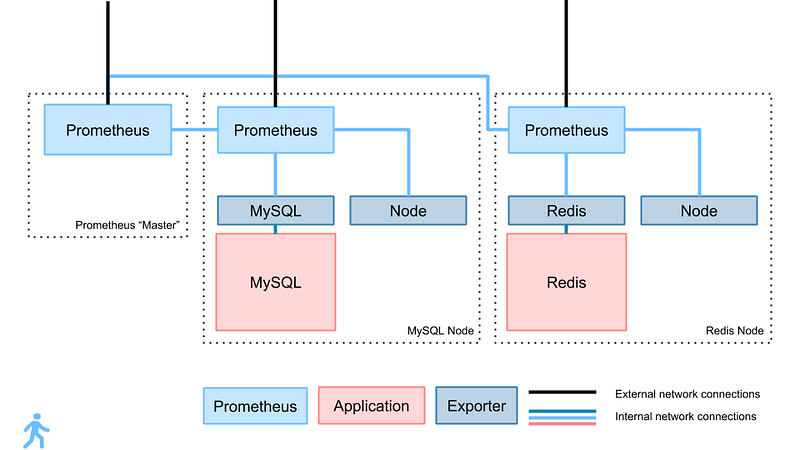
Why
So, at my company we went through several iterations of implementing Prometheus over the last twelve months prior to landing on this design.
Initially, I’m sure like most, we simply implemented the exporters, exposed them over a public interface firewalled to a limited set of IPs and called it a day. This had some security implications, so we then went through some additional evolution upgrading all metric data to be tunnelled over TLS via a reverse proxy to most nodes, but still some problems. Finally, we arrived at this design which seems to work fairly well.
However, to understand why this design pattern makes sense it’s worth evaluating some of the problems that we had along the way.
Security
First, it turns out that even time series data can contain some secret data. Prometheus works by attaching certain metadata about the things that it tracks in terms of key→value pairs. Due to some less than ideal planning, the CurlFS filesystem mount on one machine included the password in its /etc/fstab entry, in turn directly exported to Prometheus.
This was quickly caught and re-mediated during the implementation of the tooling and the CurlFS endpoint was on a local network — inaccessible to the outside world. However it scared us enough that we decided that this “safe” data should always be both encrypted, and protected with a password.
We implemented this by reverse proxying all metric connections via either NGINX or Apache, reusing what was available on the system.
However, this introduces significant configuration complexity. In many cases a machine is responsible for several application services, and it is fragile to be responsible for managing the egress of all those services directly. So, instead, drop a single Prometheus server on the node to aggregate all services, and simply secure this.
This additionally allows granting access to specific Prometheus views to specific people. Federation becomes a primitive sort of access control.
Network partitions
Prometheus requires a reliable network connection to its targets. It works by querying the target at a specific time, and recording the metrics supplied — this is how it’s able to scale so largely a key part of its architectural simplicity.
However, as enumerated by the infamous list “Fallacies of distributed computing”, this can be problematic. Number 1 on this list is:
“The network is reliable”
This lesson was brought home in a super unusual circumstance recently where a data-centre provider experienced an outage which terminated all their network equipment for a small period of time.
Of course, alarms started going off that machines could not be reached, and we began looking into the issue. However, because machines could not be reached we were effectively blind to the issue. Further, when the machines spontaneously recovered we were also unable to see historical data which would have allowed us to make the conclusion that this was network related.
Accordingly, we now run a copy of Prometheus behind the network failure zone, such that even in the worst case and there is a network problem we can look historically back at the data once it has recovered and determine what the cause of the issue was.
Reproducability and tooling consistency
One of the more interesting lessons that has become apparent while rolling out Prometheus across the organisation is that developers who are not forced to use it while debugging production systems will never learn how to use it. Instead, they will learn to use other tools they have access to; top, sysdig etc.
However, we do not want to add our testing systems to our production monitoring tooling. The goal of monitoring is to generate actionable alerts and provide the data necessary to debug the issue; the key part here being actionable. Testing systems failing are not actionable alerts — that’s a standard part of the development lifecycle. So, we cannot include our testing systems in our production data.
To resolve the issue, we instead run a copy of Prometheus with each testing system. This can then be used to query the performance of the testing system with exactly the same tooling that will be available in the production system, and can later be used in the production environment.
Developers are then able to become familiar with a single, always available set of tooling.
Load
Though not a huge issue for us just yet, Prometheus will eventually hit a bottleneck in terms of how much throughput it can handle. While we have a significant amount of room n which we can vertically scale Prometheus, it’s nice to have a design in which we can almost indefinitely roll it out.
Prometheus connects a vast amount of detail about the system. In the majority of cases, we do not need this level of detail. We need only enough detail in our authoritative Prometheus system to centralise alerting — considerably less than that which it normally provides.
During the configuration of alerting, we can configure Prometheus to collect only data that matches a given set of criteria. The rest is not deleted, it is simply not forwarded to the authoritative server.
This allows us to scale up our deployment to a far greater level than I can anticipate we will need.
Stakeholder Visibililty
At Sitewards, we work with many different organisations on the development and release of software. Many of these stakeholders are also primarily engineering companies, working on different parts of the application or an in house development team that we are teaching to work effectively with some software we specialise in.
We do not want these teams of people to access our entire network visibility infrastructure. However, by federating Prometheus we can allow them access to the areas in which they are developing. Further, they are able to contribute and modify the behaviour of this area.
This allows a more open, transparent infrastructure design and the development of a common language when debugging issues.
Architecture
Prometheus works by making HTTP requests to an endpoint that exposes data in a specific format. Something like:
foo_bar_baz_seconds_total = 5800091230128So long as the application exposes a HTTP endpoint of this format, Prometheus can be configured to query it.
However, in a moment if extremely clever insight, the Prometheus developers also allow Prometheus itself to be queried in this way. Not only for the metrics that it itself produces (monitoring for monitoring!) but for all of the metrics it has collected on behalf of other systems.
This makes federating Prometheus extremely straight forward:

Prometheus can be simply “pointed” at another copy of Prometheus, and will collect the metrics associated. In the example image above, we’re even federating Prometheus on top of federated Prometheus.
Determining Failure Boundaries
I do not know of any simple rules to determine network failure boundaries. In the typical example of my machine connecting to a website, it would be something like:

In each of these steps traffic is being routed, transformed or otherwise modified. There are cables or other mediums that connect services from point 1 to point 2. However, within each of these contexts we can determine a likely failure rate. Accordingly, it’s useful to have diagnostic information at each of these levels of the application stack.
Practically, there are many of these that we do not control. We have no influence over the network traffic decisions our ISP makes, nor the cloud provider — simply the networks either side of these hops. So, we usually just put a Prometheus on both sides, and when something breaks in the middle start probing the network with mtr and ringing people to yell at.
However, the key point here is to be deliberate about estimating where in the architectural design of the application failure will happen, and be sure that there is a Prometheus sever on the inside of that failure to continue to collect data even in the case that external systems cannot continue to operate.
Conclusion
We have been playing with Prometheus for approximately 18 months now. Our implementation has not been without issue, and it’s usage is still limited to those with specialist knowledge of server skills. A combination of dramatic ups-killing of our organisational knowledge of this area and the continued work to make these tools easier to digest and understand gives me hope that we will be able to more effectively design and implement resilient systems in future.
However, there are still many lessons to learn along the way; one of which was “federate monitoring”.