


On continuous integration and delivery
Looking for a fuller version of this article with pretty syntax highlighted code and additional tips & advice? Check out the original on…


Looking for a fuller version of this article with pretty syntax highlighted code and additional tips & advice? Check out the original on littleman.co.
Recently I have had the opportunity to join teams employing a number of different approaches to continuous Integration and Delivery (CI/CD):
Version Control: Scripts embedded in the git repository, executed as a result of git events
GUI: Scripts written and uploaded to a server, executed on arbitrary events (time, git hooks)
None: Scripts sitting on a bastion server, executed as required
In all cases the team had a set of reasons for employing the solution the did, as well as stories as to why that Particular solution works best for them.
Because I have both been able to get a view across these teams and have in the past build several systems that reflect each design I felt it reasonable to try and explain how I design them now, given that experience, as well as what the characteristics of a “good” pipeline are.
To ensure that we’re on the same page let’s start by defining CI/CD:
Definitions
One of the early adopters and more vocal organisational proponents of Continuous Integration, ThoughtWorks, defines CI as:
…a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early[1]
They go on to define Continuous Delivery:
…the natural extension of Continuous Integration, an approach in which teams ensure that every change to the system is releasable, and release any version with the push of a button[2].
Even given these definitions too understand how to operate CI/CD now it’s first worth understanding how CI/CD came to be.
A little history
Though the iterative model of software development can be traced back to the 1950s[3] it was previously more common for software development to go through distinct phases, not unlike a construction or other major project:

This is referred to as the “waterfall” pattern and it makes sense, presuming:
A stable set of requirements
A stable market demand
Unfortunately neither are generally true of software project and the approach quickly ran into issues. The issue most prescient to this article is called “integration pain”, and denotes the period of time in which developer work is reconciled and tested together before release. Martin Fowler describes the story:
My manager, part of the QA group, gave me a tour of a site and we entered a huge depressing warehouse stacked full with cubes. I was told that this project had been in development for a couple of years and was currently integrating, and had been integrating for several months. My guide told me that nobody really knew how long it would take to finish integrating[4].
In addition to this integration pain the challenges associated with shifting requirements and shifting consumer expectations mean that modern software projects are rarely “done”, and instead burdened with attempting to meet a constantly shifting target. Software released in the “waterfall” pattern is difficult to maintain in a reasonable way following its release and bugs that are discovered later in the process are up to 15 times more expensive to fix than those discovered earlier[5].
As a mechanism to address these and other issues with the SDLC Kent Beck developed the Extreme Programming (XP) approach, the precursor to the “Agile” software development approach[6]. Among other things XP endorsed the use of continuous integration as a mechanism to ensure that integration pain was much reduced, bugs were caught early and the software could be adjusted to new requirements. Kent used this approach with various projects including the “Chrysler Comprehensive Compensation” project with Martin Fowler[4], who would later go on to publish and popularize this approach.
While not a requirement for continuous integration[4], CI servers became a popular method of implementing this approach. ThoughtWorks were among the first with their “Cruise Control” serer, released in 2001[7]. Later Sun Microsystems developed “Hudson”, released in 2015[8], the precursor to the infinitely popular and still widely used Jenkins CI. Jenkins was developed as a result of disputes with Suns purchasers Oracle[8] and released in 2011[9].
Jenkins later introduced the concept of “Workflows”, which were builds that could be checked in to version control instead of configured in a GUI[10] and marking the shift to CI systems entirely driven by VCS.
It is difficult to map when containers started being used as environments in which to run CI jobs as the history of containers goes far further back than one might imagine[11] however the earliest development of the Docker plugin for Jenkins goes back to 2014[12]. The rise of the popularity of Docker and its excellent ephemeral environment tooling mean that many modern CI systems consume Docker containers as their only build environment[13],[14],[15].
This brings us to the current era where the majority of CI/CD tools are built on top of:
Version control
Docker
Multi-stage workflows
In this case this post will be talking primarily about the Drone build server which is an excellent open source implementation of this technology.
CI/CD as part of the Software Development Life Cycle
While the historical context of how CI/CD was implemented is super useful for providing understanding of the pressures that generated CI understanding how it fits into the software development life cycle (SDLC) first requires an understanding of how the SDLC is currently architected. One of the most common patterns of development is called the ‘feature branch’ workflow[16].
The work begins with the description of requirements in a ticket, usually in the form of a “user story” or “bug report”. These are tickets that either a new application behaviour or some circumstance in which the application does not behave as expected. I would then review the ticket, asking questions for clarification or to ensure that the feature is being used as expected before adding it to the work queue.
Implementation starts by updating the local copy of version control. The canonical branch in all version control systems I use is called master and is the branch that is either deployed on production systems directly or used as a base to create a "release branch" to be deployed. It is the version of the code on which all future work should be based:
# Switch to the master branch
$ git checkout master# Pull any recent changes into the local copy of master
$ git pullImmediately after ensuring my local branch is up to date I switch to a new “feature” branch. This branch is temporary and allows me to make changes to the codebase in a way that is not going to affect other people:
# Create a feature branch
$ git checkout -b my-awesome-featureFrom here, I do development:
$ cat <<EOF > index.php
<?php
echo "Hello World!"
EOFOnce development has been completed and tests have been written I commit the changes and push the branch up to the origin to save my work
$ git add index.php
$ git commit -m "Add my awesome feature"
$ git push origin my-awesome-featureI will then create a pull request[17]:

And we see the first CI checks. In the image above we can see “Some checks have not completed yet”, with a note that Drone is running a “PR” job. It is here that CI is responsible for enforcing code safety checks such as unit, integration and smoke tests:

Following the successful completion of these tests the PR is sent to a colleague for their review. If that colleague is happy with the changes they will merge the work into the mainline.
Once the work is merged in to the master branch, CI is responsible for deploying the work to a production system:

Around 3 minutes after I (or my colleague) has merged code in the work is in production and facing users.
That’s it!
The building blocks of CI/CD
Given the above development workflow we can see our CI/CD system has several different responsibilities, split into two areas of focus:
Ensuring the program remains correct before work is merged in to the
masterbranchMaking the new software available to users
This work is usually broken up into a staged process. The following is an example of the “Pull request” process:

These sets of processes are usually referred to as a “Pipeline”, named after the computing definition:
a set of data processing elements connected in series, where the output of one element is the input of the next one[18].
There are several different components required to create such a CI/CD pipeline[19],[20],[21]:
Version Control: Contain the current state of the software, be that the canonical version or a patch that has been proposed e.g.
git,svn.Linter: A tool that analyzes source code to flag programming errors, bugs, stylistic errors, and suspicious constructs e.g.
phpcs,yamllint.Unit Tests: A software testing method by which individual units of source code, sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures, are tested to determine whether they are fit for use e.g.
phpunit.Integration Tests: The phase in software testing in which individual software modules are combined and tested as a group.
Task Runner: A tool that allows aggregating tasks such as application compilation, testing and deployment behind a single interface e.g.
make,robo.Deployment Manager: A tool that manages replicas of the software deployed for production, facing or testing purposes behind a single interface e.g.
helm.
These tools are not specific to CI/CD but are rather general tools that are designed to track, ensure correctness and deploy the software. Accordingly they should be set up to be executed both in and outside the CI/CD environment with the environment itself being as “dumb” as possible. This can be done by putting the logic to run these tests behind a task runner and invoking that task runner both in the development and the CI/CD environment:
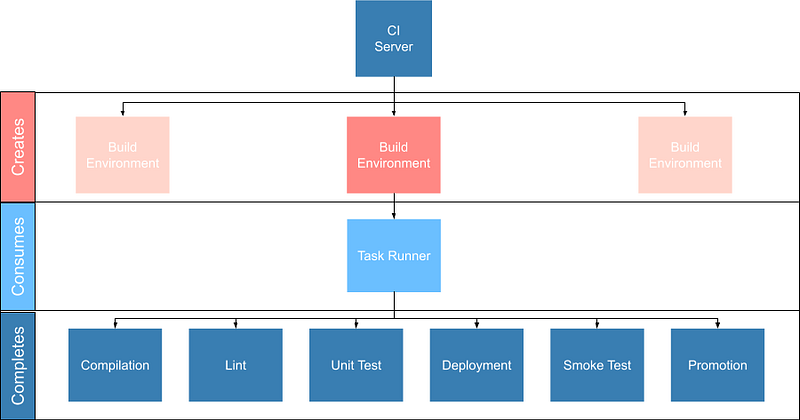
Practically speaking this means instead of configuring pipelines with large sets of commands:
$ echo $B64_GOOGLE_SERVICE_ACCOUNT | base64 -d > $GOOGLE_APPLICATION_CREDENTIALS
$ gcloud auth activate-service-account --key-file=$GOOGLE_APPLICATION_CREDENTIALS
$ gcloud config set project $GOOGLE_PROJECT_NAME
$ gcloud container clusters get-credentials --zone $GOOGLE_PROJECT_REGION $GOOGLE_GKE_CLUSTER_NAME
$ helm upgrade --install --namespace www-littleman-co www-littleman-co deploy/helmThe pipeline should be invoked only with a single command with some argument indicating which task to run:
robo deploy --environment=productionThis separation of responsibilities into the task runner, deployment manager and CI pipeline allows the reuse and debugging of the majority of the pipeline locally, switching between CI/CD services without undue cost and makes the pipelines as simple and predictable as possible.
Writing the task
As discussed, the pipeline consists of a set of steps that need to be executed prior to verifying the codebase is still correct or deploying the software to some environment. Further, these steps should be executable both on the local machine and in the build pipeline in exactly the same way. The way to implement this is via a task runner, such as Robo:
$ robo init
~~~ Welcome to Robo! ~~~~
RoboFile.php will be created in the current directory
Edit this file to add your commands!$ cat RoboFile.php
<?php
class RoboFile extends \Robo\Tasks {}We then add our tasks in our task runners domain specific language; in this case, by writing a public function in PHP:
class RoboFile extends \Robo\Tasks
{
/**
* Runs lints over the codebase
*
* @option files A space separated list of files to lint
*/
public function lint()
{
$this->taskExecStack()
->stopOnFail()
->exec('yamllint .')
->run();
}
}That allows us to test the task locally:
$ robo lint
[ExecStack] yamllint www.littleman.co
[ExecStack] Running yamllint www.littleman.co
www.littleman.co/config.yaml
24:3 error wrong indentation: expected 4 but found 2 (indentation)
42:81 error line too long (101 > 80 characters) (line-length)
46:81 error line too long (123 > 80 characters) (line-length)
...And adjust the check (or the code) until it works as expected:
cat <<EOF > .yamllint
---
# Configuration for the linter that applies some sane defaults
extends: defaultignore: |
deploy/helmrules:
line-length:
max: 120
braces:
max-spaces-inside: 1
EOFThe task should work successfully before being committed:
$ robo lint
[ExecStack] yamllint .
[ExecStack] Running yamllint .
[ExecStack] Done in 0.171s$ echo $?
0 # SuccessAfter which the step can be committed to version control and is ready to be consumed in the CI/CD pipeline. Steps can be written for any number of tasks:
$ robo list...Available commands:
deploy Pushes a change to a given environment
help Displays help for a command
lint Runs lints over the codebase
list Lists commands
rollback Rolls back a change to a given environment to the previous version of that change.
application
application:compile Compiles the static site
container
container:build Builds containers. Available containers are those at the path "build/containers"
container:push Pushes containers
self
self:update [update] Updates Robo to the latest version.
test
test:integration Runs integration tests on the codebase
test:smoke Runs smoke tests on the codebase
test:stress Runs stress tests on the codebase
test:unit Runs unit tests on the codebaseHowever, they should all work and be useful locally before they’re consumed in the pipeline.
Designing the pipeline
Choosing a CI/CD server
There are many different CI/CD tools that are available, both implemented as open source and commercially supported. However, some tools are better than others. To me, the most important characteristics are:
Driven by version control
Simple & Clear
Docker based
Well integrated into project management tooling
Capable of building a “Directed acyclic graph” (DAG)
There are several tools that match this criteria, including:
Drone CI
Circle CI
BitBucket Pipelines
GitLab Pipelines
There are likely many more. However, of the tools I’ve tried so far I prefer the Drone build system. It is an excellent combination of simple, opinionated and well integrated into existing build tooling.
Writing the job
Most tools specify build configuration with a file or folder in the project root, and Drone is no exception with its drone.yml specification.
A minimal configuration that lints every time the code is pushed to the upstream server would look like:
$ cat <<EOF > .drone.yml
---
kind: "pipeline"
name: "lint"
steps:
- name: "lint"
image: "debian:stretch"
commands:
- robo lint
EOFCommitting and pushing it should trigger the build:
# git add RoboFile.php .drone.yml
$ git commit -m "Create an initial build configuration"
$ git push origin ad-hoc-ci-cd-demoWhile this invokes the build process, the build itself is not successful:
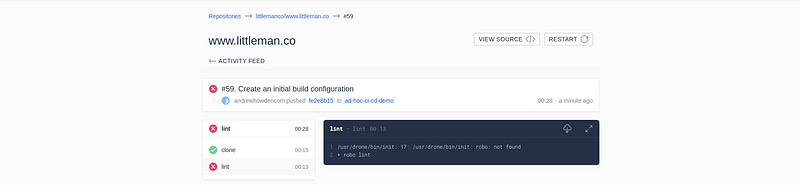
The build environment is the tools to invoke the task runner and do the required ${WORK}. There are two possible solutions to this:
Install the tools in the pipeline
Create a container that includes the build tools
Of these options. #2 is far better. It allows much faster builds, prevents flaky builds due to software upstreams being down or the network being flaky and fixes the build software to a “known” version.
Often, there are pre made images that are suitable for our purpose. However, unless the heritage of that image is trusted its better to simply write one. If the build task is simple and it’s possible to write an image that does a single thing it’s reasonable to publish the image. However, more likely the build will require some custom tools not regularly bundled together.
An example would be:
FROM debian:stretch# Some system upgrades
RUN apt-get update && \
apt-get dist-upgrade --yesRUN apt-get install --yes \
# "Basic" tools
curl \
python python-pip \
# Task runner runtime
php && \
# Linting Tools
pip install \
yamllint# Install the task runer
RUN curl -O https://robo.li/robo.phar && \
chmod +x ./robo.phar && \
mv ./robo.phar /usr/local/bin/roboThe logic to build (and push) this new Dockerfile can be embedded in the same task runner:
/**
* Builds containers. Available containers are those at the path "build/containers"
*
* @option container The container to build
*/
public function containerBuild($opts = ['container' => 'web'])
{
$refspec = exec('git rev-parse --short HEAD');
$containerName = self::CONTAINER_NAMESPACE . '--' . $opts['container']; $this->taskDockerBuild(self::CONTAINER_PATH . DIRECTORY_SEPARATOR . $opts['container'])
->tag($containerName . ':' . $refspec)
->tag($containerName . ':latest' )
->run();
} public function containerPush($opts = ['container' => 'web'])
{
// Omitted for brevity
}Once the image has been built & pushed to the repository we can consume it in our build configuration:
---
kind: "pipeline"
name: "lint"
steps:
- name: "lint"
image: "gcr.io/littleman-co/www-littleman-co--build:fe2e8b1"
commands:
- /usr/local/bin/robo lintAnd the build should work as expected:
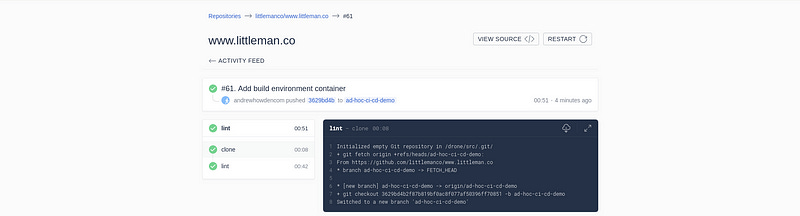
This repeats for however many tasks the build should consist of; lints, tests and eventually even the deployment.
The pipeline
So far we are able to write tasks that do some analysis work on the build, already a huge step forward in our ability to ensure system correctness over time.
However, a pipeline is not a single job; rather, it is a series of jobs that are triggered in a particular circumstance. There are two that I use regularly:
Pull Request: A workflow designed to ensure changes do not break the system. Triggered by the creation of the pull request and blocking the pull request from being merged until the build is successful.
Deployment: A workflow designed to push the “known good” code to a production system
They usually look something like:

The specific steps involved depend on your deployment model, available tests or other requirements. However there can be multiple workflows and each workflow can consist of an arbitrarily complex set of steps. The pipelines are usually invoked by some sort of “trigger” mechanism; some signal to the CI tool to start a specific pipeline. In the case of Drone the configuration is called just that — triggers.
There are situations in which it is desirable to deploy to production in a hurry, without verifying the software for correctness, such as a security issue or other disaster management process. Accordingly, the production pipeline should be less than 5 minutes to complete and extremely reliable.
Pull Request
To create a “pull request” workflow, the configuration looks like:
---
kind: "pipeline"
name: "lint"
steps:
- name: "lint"
image: "gcr.io/littleman-co/www-littleman-co--build:da8b695"
commands:
- /usr/local/bin/robo linttrigger:
# Execute this process every time a new pull request is opened
event:
- pull_requestJobs can be executed in parallel by specifying multiple pipelines that have the same dependencies:
---
# Steps are omitted for brevity in the post
kind: "pipeline"
name: "lint"
steps: []
trigger:
event:
- pull_request
---
kind: "pipeline"
name: "unit-test"
steps: []
trigger:
event:
- pull_requestAnd it’s possible to “gate” steps on the success on other steps by using the “depends_on” node:
---
# Steps are omitted for brevity in the post
kind: "pipeline"
name: "lint"
steps: []
trigger:
event:
- pull_request
---
kind: "pipeline"
name: "unit-test"
steps: []
trigger:
event:
- pull_request
---
kind: "pipeline"
name: "integration-test"
steps: []
trigger:
event:
- pull_request
depends_on:
- lint
- unit-test
---
kind: "pipeline"
name: "stress-test"
steps: []
trigger:
event:
- pull_request
depends_on:
- lint
- unit-test
---
kind: "pipeline"
name: "smoke-test"
steps: []
trigger:
event:
- pull_request
depends_on:
- lint
- unit-testThis gives us our ability to create our graph. So far we have generated only the first two steps:

However, we can see our pipeline working as expected:
Deployment
Implementing the deployment task is exactly the same process, varying only in the triggers. However, one common use case for production is being able to manually gate builds based on some human intervention. In the case of Drone this is termed “Promotion”.
The first part of the build automatically pushes the most recent master change to the “canary” environment:
---
kind: "pipeline"
name: "container"
steps:
- name: "container"
image: "gcr.io/littleman-co/www-littleman-co--build:d7c8edd"
environment:
GOOGLE_SERVICE_ACCOUNT:
from_secret: GOOGLE_SERVICE_ACCOUNT
# Required to build container
privileged: true
commands:
# Enable img to push to docker registry
- img login -u _json_key -p "$GOOGLE_SERVICE_ACCOUNT" https://gcr.io
- /usr/local/bin/robo application:compile
- /usr/local/bin/robo container:build --container=web
- /usr/local/bin/robo container:push --container=webtrigger:
branch:
- master
event:
- push
---
kind: "pipeline"
name: "canary"
steps:
- name: "canary"
image: "gcr.io/littleman-co/www-littleman-co--build:d7c8edd"
commands:
- /usr/local/bin/robo deploy --environment=canary
trigger:
branch:
- master
event:
- push
depends_on:
- containerHowever, the code does not make it all the way to the production system. That configuration is gated by a trigger called the “promotion” trigger:
---
kind: "pipeline"
name: "production"
steps:
- name: "deploy"
image: "gcr.io/littleman-co/www-littleman-co--build:d7c8edd"
commands:
- /usr/local/bin/robo deploy --environment=production
trigger:
event:
- promote
target:
- production
branch:
- masterThis trigger requires that the developer execute the following command in order to “promote” the canary build to the production system:
drone build promote littlemanco/www.littleman.co 100 productionWhere:
littlemanco/www.littleman.cois the repository100is the build numberproductionis the intended environment
With this we achieve the desired “two step” build process:
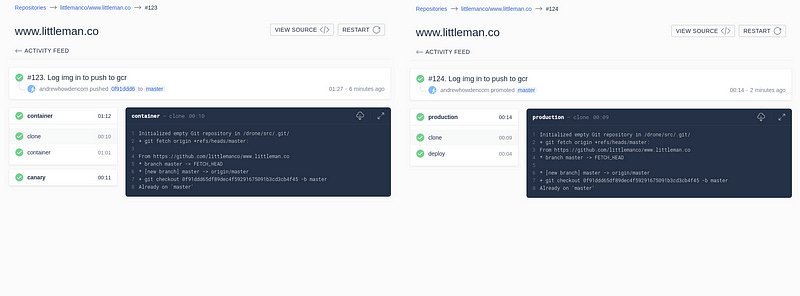
Where step 1 is executed automatically on anything being added to the master branch, whereas step two requires a human to “promote” the build. At the time of writing it is only possible to trigger the promotion via the CLI.
In Conclusion
Continuous integration & delivery has become a fairly essential part of software development. It augments the software delivery life cycle with additional correctness checking to find bugs earlier and dramatically reduces the cost and risk associated with pushing changes to production. There are many CI/CD servers however Drone implements all required features for the vast majority of software projects and is open source and trivially installable. With Drone we constructed a multi-step build cycle stubbing out lints, tests and other correctness checks common software, as well as stubbed out a workflow for continuous delivery.
That’s it! This post got a bit long, and I did not get to cover all of the things I would like to. However if you made it this far and you enjoyed it be sure to voice yourself on GitHub, and I’ll keep writing this stuff up.
❤
References
“Continuous Integration.” https://www.thoughtworks.com/continuous-integration .
“Continuous Delivery.” https://www.thoughtworks.com/de/continuous-delivery .
C. Larman and V. R. Basili, “Iterative and Incremental Development: A Brief History.” http://www.craiglarman.com/wiki/downloads/misc/history-of-iterative-larman-and-basili-ieee-computer.pdf , Jun-2003.
M. Fowler, “Continuous Integration.” https://martinfowler.com/articles/continuousIntegration.html , May-2006.
A. Saini, “How much do bugs cost to fix during each phase of the SDLC?” https://www.synopsys.com/blogs/software-security/cost-to-fix-bugs-during-each-sdlc-phase/ , Jan-2017.
M. Fowler, “Extreme Programming.” https://www.martinfowler.com/bliki/ExtremeProgramming.html , Jul-2013.
“Cruize Control.” https://en.wikipedia.org/wiki/CruiseControl .
“Hudson (sofware).” https://en.wikipedia.org/wiki/Hudson_(software) .
“Jenkins (software).” https://en.wikipedia.org/wiki/Jenkins_(software) .
V. Farcic, “The Short History of CI/CD Tools.” https://technologyconversations.com/2016/01/14/the-short-history-of-cicd-tools/ , Jan-2016.
A. Howden, “What is a container.” https://www.littleman.co/articles/what-is-a-container/ , Mar-2019.
magnayn, “Initial Commit.” https://github.com/jenkinsci/docker-plugin/commit/50ec99d , Jan-2014.
“GitLab (EE) CI.” https://docs.gitlab.com/ee/ci/ .
“Use Docker images as build environments.” https://confluence.atlassian.com/bitbucket/use-docker-images-as-build-environments-792298897.html , Apr-2019.
“Plugins Overview.” https://docs.drone.io/plugins/overview/ .
“Git Feature Branch Workflow.” https://www.atlassian.com/git/tutorials/comparing-workflows/feature-branch-workflow .
“Creating a pull request.” https://help.github.com/en/articles/creating-a-pull-request .
“Pipeline (computing).” https://en.wikipedia.org/wiki/Pipeline_(computing) .
“Linter (software).” https://en.wikipedia.org/wiki/Lint_(software) .
“Unit Testing.” https://en.wikipedia.org/wiki/Unit_testing .
“Integration Testing.” https://en.wikipedia.org/wiki/Integration_testing .