
Incident Commander
How to maximize the capabilities of those responding to production outages

💡 You can also listen to this post via a podcast or find it on YouTube with some handy visuals.
I’ve been part of the “incident commander” at a large, multi-national European eCommerce fashion company for the last couple of years. Through this, and my time as a Site Reliability Engineer, I have been exposed to numerous incidents, from the occasional “… this is not an incident. We can just deal with this tomorrow” to the “we need the CTO on the phone right now”. It’s a hugely exciting role that I would encourage peers to consider as part of their personal development.
To that end, let’s go into what an “Incident Commander” is, their roles and responsibilities, how to prepare for the role, and what the role looks like in practice.
Incident Response
Rather than dig into the incident response details, I’d encourage you to read the article “I hereby declare this an incident” and “Help! I’m now on call!”. They go through this in substantially more detail.
For incident commanders, a few things are worth calling out especially. These include Severity, Stakeholders and Maturity.
Severity
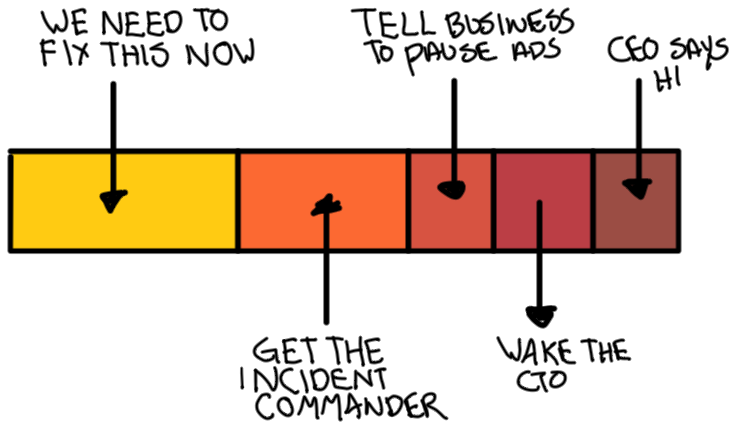
The severities that we see as an incident commander can vary pretty widely; everything from “someone deployed something bad and should roll it back” to “this is going to appear on the news tomorrow, and we’d better wake up the crisis management team to prepare the required press releases”. We’re usually the most senior stakeholder in the room — indeed, the most empowered unless a VP or CTO turns up — and we thus need to make a set of decisions factoring in the current level of impact, the risk of future impact and the likelihood of recovery.
To that end, we need to understand the significance of our issue quickly.
Stakeholders
On paper, only a few people are involved in incident response — the responder fixing the issue, the scribe making notes and you as the incident commander.
In practice, as the issue gets more significant, many stakeholders turn up. We have:
Management is looking for clarity on the current issue and to make it clear that it deserves the focus of all people required. Also, to offer help and coordination.
Sideline Experts who are watching the incident on a public channel or otherwise doing off-book investigation and who have learned something they believe is beneficial.
Product Owners who are suddenly powerless to do their work and are watching their hard-earned customer trust wash away.
Non Experts are trying to help by supplying additional information or reporting the issue in parallel without understanding the existing context.
Each of these stakeholders requires a level of coordination to ensure they either can contribute to or at least do not hinder the response.
Maturity
In principle, an organisation optimizes to ensure things are available. They usually have a group of people tasked with this responsibility and allocate those people the time and effort required to practice and improve their response.
In practice, an organization comprises a diverse set of people, each of whom has a unique set of expertise and capabilities. Sometimes those capabilities are less developed than we might expect, given a person’s assigned responsibility as an on-call engineer.
They might:
Freeze. Due to an incident's sheer stress, a responder might not think clearly and either freeze entirely or get stuck hyperfocused on an irrelevant part of the investigation. This is understandably exaggerated if that responder also triggered the incident.
Offload Responsibility. A responder might review their systems, conclude nothing is wrong, and thus, it’s someone else problem. They’ll involve them and then leave. This is understandable but unacceptable during response — information usually evolves too quickly to step away before it’s repaired.
Not know. A responder might not know how to debug a system, where a systems telemetry is or what the consequence of a given decision might be for the business.
These are all surprising during the process of a response, but over a long enough time happen predictably. It’s part of an incident commander’s mandate to try and help responders overcome these challenges.
Role
So, an incident has happened, and the incident commander has been paged. They’re reading the chat and understand the severity of an incident, the stakeholders that are appearing and the maturity of those involved. What’s their actual role in this mess?
An incident commander is tasked with structuring the response to minimise the impact on the business. The practicalities of this include:
Structuring Communication
An incident is a high-stress moment with many people coordinating around a single issue. Frequently, people start to take shortcuts with their communication, and messages become things like:
A: flop system is broke
B: broke?
A: yeah broke it doesn’t work anymore
C: A what does the graph say
B: it works for me
A: no its broke
Or similarly vague requests. With stressed people, this quickly deteriorates and can end up with people either getting “snippy” with each other, making demands or working in parallel and not talking. As more and more people join the chat, it becomes unworkable, and we lose valuable time just understanding each other rather than analyzing the problem to intervene.
As incident commanders, we need to intervene and clearly set communication expectations. Often we can do this simply by reading through the thread and articulating everything that’s happened so far in a status message. For example,
IC: So far, I understand the customer experience impact is
* flop system
Our underlying hypothesis of this are:
* we’re out of disk space (being verified by A)
* we’re overloading CPU (being verified by B)
at this time, our estimated time to recovery could be up to 1hr and is very unpredictable. Please add a ➕ is this is correct
Such a message clearly sets the expectation for how communication should be and combines a bunch of communication happening in bits between stakeholders piecemeal.
This can quiet the thread until there’s a discovery or intervention. Whenever there is, it might still appear piecemeal:
A: disk is full
We can tidy this up by both setting the expectation about comms and clarifying the actual data:
IC: A, I am struggling to understand your message as it does not contain the context I need. Do you mean that the disk with the ID a-service-disk has zero free space left according to the graph “https://…”
A: Yep sorry will add this in future
After which the communication usually improves.
Making Decisions
As the incident response goes on, there often comes a point when a responder can intervene, but that intervention comes with some risk. For example, they might disable a payment method even though it is used by 50% of users in that country, even if it is broken, or they might need to make many products unavailable while data is repaired. The responder might be able to supply some information about the consequences but does not feel sufficiently empowered to make that call.
An incident commander is empowered to make these decisions. They need to balance the impact on the customer experience, the customer experience given the alternative and the impact on the business. They need to assess whether other, better-informed stakeholders are available to make the decision or whether it is better to make it sooner. Ultimately, they need to provide a path forward for the responder.
There are no correct solutions here, but commanders are expected to know enough to make reasonable decisions the majority of the time.
Managing Stakeholders
As earlier mentioned, many stakeholders will turn up during a response — both those who are supposed to and those who are trying to be helpful. The problem is those stakeholders can start to distract those that are actually repairing the issue, either with requests for clarification (usually management) or helpful ideas about restoring the service (other engineers)
To repair a system — especially if the underlying failure is non-intuitive — the responders need to be able to focus. This means that while the messages addressed to responders are well-intentioned, they are also degrading the response.
As incident commanders, we need to take away as much of the burden of communication from responders as possible and work to manage the expectations of those trying to contribute with only the information we have. We can encourage people to send technical insights they have to us privately to keep them out of the main thread, and if we catch one that is especially useful, ask the contributor to surface it in the main thread and join the response.
We also need to communicate proactively with non-technical stakeholders, translating the technical findings of the incident so far into information that these stakeholders can take action on. This could be as simple as clearly conveying the current customer experience, giving an estimation of time to recovery or simply reassuring people that the response is happening and just to be patient.
Manage large incidents
Occasionally some incidents are so substantial they require multiple parallel efforts to restore system functionality. This could be a whole team executing a repetitive task (e.g. repairing DNS records) or many different teams figuring out how to repair their service (e.g. shifting many different services out of a broken availability zone).
During such a response, it is up to the incident commander to survey the available people and then to task either specific people or teams with people with tasks that they should complete. The incident commander should also set up an ad-hoc management process — often just a Google Sheet or Doc — to keep track of these tasks and identify any people who are stuck or need intervention.
This can take substantial mental effort. The critical thing in these cases is to maintain an overview of the current impact, hypothesis, interventions and people doing tasks. This means that some of the incident commander's responsibility should be delegated to other incident commanders or senior colleagues. For example, managing communications, communicating with management or updating sheets can all be delegated to someone else while the incident commander maintains an overview.
Kick-off crisis management
There are occasions when a given technical issue has such substantial ramifications that it will mean the company either loses customer trust or money or appears in the news. All of this is beyond the usual remit of incident response, but there are parts of the company that are designed to cope with these challenges.
An incident commander should kick off these crisis management teams and empower them with what they need to control the narrative around what is happening with the system. Occasionally, these teams will come back with requests (e.g. “Can we put up a notice here” or “Can we identify customers to apologize and send a voucher”); the commander has to prioritize and implement these requests against the backdrop of the incident.
Off the beaten path
Lastly, there are occasions when something happens simply that no one planned for. Still, it is sufficiently urgent that it bypasses all software deliverables and is worth as much effort as we can bring to bear on it. One recent example is security issues that affect many systems (e.g. log4j) and are outside the normal security response process.
Incident Commanders are frequently involved in these incidents for their experience managing such urgent tasks, relationships with responders, and credibility within the community. While the incident might not follow the traditional process, the commander can still help deliver a critical and immediate business requirement.
Preparation
What characterises the incident commander role (at least, in my experience) is that it tends to be involved in issues that are outside the normal processes. This makes the role challenging, as it would be “preparing for the unexpected”, and the unexpected is … well, unexpected.
That said, there are things that incident commanders should have:
Practice
An incident response process is generally designed to empower responders to prioritize, communicate and respond to production issues, but it also usually doesn’t say much about the response. The response depends on the specific technical stack, the business impact, the stakeholders and other organizational contexts.
The only way to understand what responders are going through is to be a responder. Because incident commanders are usually only called for issues more critical than the “average” incident, they should have experience with similarly critical incidents.
This allows them to build empathy with responders as they go through their most challenging professional experience so far and build a toolkit to understand the impact, manage these responders, or otherwise coordinate incidents.
Once they have that experience, they should join the incident commander rotation in the shadow role to get perspective on the other side of that responsibility and build the required business context and relationships.
A broad business understanding
As mentioned earlier, incident commanders will tend to be involved in more substantial issues, and occasionally, they need to make time-sensitive decisions that can broadly impact the customer experience.
They can only do that if they also understand the business, the customer experience, and the software architecture and can make a judgement call as to which is the better technical path to follow.
Gaining a better understanding of the business is dedicating time to learning it, reading each domain's top-level and significant strategies, and then understanding the approximate software architecture. It will evolve, but a business’s core deliverables are stable over many years.
Good stakeholder relationships
Lastly, as the incident commander interacts with a broad range of stakeholders across a broad range of job roles, they must communicate in ways that suit each stakeholder. Additionally, they have (hopefully) established this communication outside the bounds of the incident itself. Good relationships allow much of the communication to be implicit, and stakeholders are more likely to trust the incident commander’s judgement until it can be reviewed.
As a pro tip, communication does not necessarily have to be two-way — being seen as a visible, technical expert with good communication skills makes life easier.
Debugging Skills
Naively, an incident commander is also expected to have excellent debugging skills and be able to reason through the behaviour of a broad range of systems.
If you are debugging an incident yourself during a response, the incident is in deep trouble.
That’s not to say it doesn’t happen — it does, every so often — but an incident commander's core value is in enabling others' excellent work rather than being a technical expert.
Where they are needed, skills in reasoning through the system in first principles (e.g. as a system of constrained resources, as a series of queues or in its interactions with the kernel) are most helpful in understanding a broad range of systems, runtimes and architectures. After that, reading the internals of different runtimes — Java, Scala, Go, Node and so on are all useful as they frequently have excellent debugging capabilities that responders didn’t know, as they’d never needed to go that deep.
In the end, all just bits flowing through the network get run on several cores and, occasionally, written to disk.
In Summary
Incident Commander is an exciting role. It exists primarily to catalyze response rather than contribute significantly to anything about the response. This means they must understand the severity, stakeholders and maturity of responders and work by structuring communication, making decisions, managing stakeholders, significant incidents or anything “off the beaten path”.
There’s no secret to preparation, save taking the time to practice — especially in incidents of the same severity that incident commanders are regularly involved in. This practice and developing a broad business understanding, stakeholder relationships and debugging skills all go a long way to making an effective incident commander.
Hopefully, this reassures you that incident commanders are, in fact, human and that, with time and effort, you, too, can join their ranks!