
Failing safely
A lesson about thinking about defining specific failure behaviours


A lesson about thinking about defining specific failure behaviours
I awoke this groggy Sunday morning with an uncomfortable amount of hangover to the chirping of my phone:

One of the more critical systems that we’re responsible for was not responding to HTTP probes with the expected result. More specifically, it was returning HTTP 500 or HTTP 502:
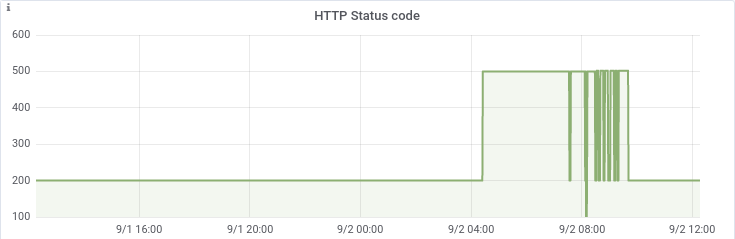
False flag #1: MySQL connections
This particular logical service consists of at least 2 different applications, which depend on on each other for various reasons. The wisdom of this aside, this means that if either application dies, they’re both dead. It also means that if one dies temporarily, the system can cascade as each system tries to request resource from the other dead system, which can’t request resources from the first.
The system did not look like it was under any sort of CPU/IO contention; indeed, it was only operating at about ~15% of its capacity. This means that the problem is likely within application specific resources. Looking at application logs, it became clear that at least some of the errors were due to a max connections limit on MySQL:
SQLSTATE[08004] [1040] Too many connections";i:1;s:3490:"#0 /var/www/__FILEPATH__ /web/lib/Zend/Db/Adapter/Pdo/Mysql.php(111): Zend_Db_Adapter_Pdo_Abstract->_connect()The system supported ~1000 PHP workers, but for some reason had only a max of 200 MySQL connections. A quick grep of the docs showed that the machine at least theoretically can support many more, and we bumped that up.
This removed the MySQL errors from the log, but the application was still dead. Looking at show processlist showed something like:
# show full processlist; # edited for brevity+------+---------+---------+------+-------+------------------+
| Id | db | Command | Time | State | Info |
+------+---------+---------+------+-------+------------------+
| 2047 | myDB | Sleep | 81 | | NULL |
...
| 2049 | myDB | Sleep | 81 | | NULL |
| 2050 | myDB | Sleep | 81 | | NULL |
+------+---------+---------+------+-------+------------------+All our PHP workers from one application to be stuck doing… nothing?
A closer look at the failing PHP processes
Next step was to take a look at one of these PHP processes. Running an strace over one of the stuck processes and the error became immediately apparent:
lstat("/var/www/__FILEPATH__/__RUN_DIR__/locks/flock_f717dc660f746b4945d4aa0ec882b7d9", {st_mode=S_IFREG|0664, st_size=0, ...}) = 0The strace kept looping over this file, attempting to acquire an flock but failing. So, the PHP workers establish connection to the database, then block on flock. MySQL mystery solved. But why lock at all?
In previous work, this application would hit a state in which it would not unlock if it failed ungracefully. Given that the system was 100% borked, it was worth simply rming the lock and seeing if the system repaid. Doing so, and restarting PHP to kill the blocked connections indeed unblocked the application, but the locks were rapidly recreated and the application block all over again.
It’s at this point the failure pattern was clear;
Application worked fine for most pages, but a particular page acquired a lock, and as other workers also hit this request would also block.
The server would run out of workers, and hit the critical failure condition.
Server would not be able to unbork.
So, to fix the server, we need to figure out why it’s crashing during the flock.
False flag #2: Flock
The application had its locking mechanism centralised in a single class and implementer, and did not appear to be called a large number of times — a good thing. However, it all looked correct.
Specifically, the application was using the Linux flock primitive. Additionally, a __destruct cleanup function was registered that both unlocked and deleted the generated lock file. There were no other references to flock apart from this correctly generated pathway, and there was nothing in the php_errors.log that indicate the PHP processes had died in a super ungraceful way, such as SIGSEGV (segfault). Regardless, PHP should release flock even in the case of SIGSEGV.
Looking through the error logs however, there were errors as the application attempted to unlock and clean up the manually deleted lock files. Those errors included a stack trace which indicated what had generated the lock — a system designed to provide weather data.
The real flag: third party service failure
That narrowed the issue down to a single unit of code, from which it was easy enough to find other errors that appeared about the same time:
Core: Exception handler (WEB): Uncaught TYPO3 Exception: #1: PHP Warning: file_get_contents(http://third.party.service/api/bork.php?x=1,y=2)This service is public, and hitting it in the browser immediately showed the problem. The request would take 60 seconds, and then fail with a HTTP 502.
This explained the entire block of errors:
Workers would try to get data from the third party service. They
flockto prevent spamming the service, and cache the data. But the service takes 60 seconds, blocking all other workers, and then no data is returned.Even with only a few hundred users, all workers would eventually hit this URL and block.
System falls over.
Deciding how to fail
We can’t do anything about the third party service. However, the problem is not that the service is down; that’s handled within the application. The problem is the request is taking a long time before it decides it’s down.
Practically, we decide the site is “dead” if it doesn’t respond in 5 seconds. Users barely wait these 5 seconds, and they certainly won’t wait 60 just to get served an error page. So, the solution implemented was to modify the application to decide the third party service was also dead if it did not respond in 5 seconds. Practically, it should have been less — but the service is already dead, and thus is not the bastion of reliability.
This was accomplished fairly simply by adding:
default_socket_timeout = 5to /etc/php/7.0/fpm/php.ini
Once PHP was restarted, the threads freed up much more quickly and the system remained stable (if still inefficient).
Lessons learned
Once this fix was in place, the service was up and running for the majority. The section that required the third party data was still dead, but it would self resolve when the third party system came alive.
To my frustration, after spending ~2 hours investigating this the third party system was fixed about 15 minutes after the hotfix was in place and the system was stable. Still, this was an interesting investigation, and provided some lessons that are worth taking away:
Be deliberate about failure
Unfortunately, the code that was responsible for the communication with the third party API is several years old, and not written by any members of the current or previous project teams — we inherited it. However, we’re still responsible for it.
The code did not factor in failure in two ways:
The third party service returned errors, and
The third party service simply did not respond
Both of these conditions are essentially guaranteed given enough project run time. In these cases, more general (higher level) fault handling picked up the failure and surfaced it to the relevant systems, but it would be possible to handle this in a couple of more graceful ways:
Using a “stale while revalidate” strategy where old data is used even though expired while new data was unavailable.
Surfacing the error directly to the client side application which can explain the error to the user, and implement a retry with exponential backoff.
When writing code, especially code that depends on networked systems it’s worth planning for failure as the default case, and success where possible. This means systems will degrade and heal gracefully as their dependencies transition from healthy to unhealthy and back.
Be proactive about declaring failure
In this case, the failure of the system was fairly limited, and only affected one particular request transaction. However, because the code would block waiting for a deliberate success or failure status, it blocked the entire system.
In this case this transaction was not critical; no user data was being saved or changed, and no money was changing hands. Failure is fairly acceptable here. Given this, it’s reasonable to decide as soon as the request is outside it’s nominal bounds it’s a failure, and return with that failure status to higher level systems to decide what to do with it.
In this case, a speedy failure is worth more than an eventual success.
The network is not reliable
Obligatorily, critical dependencies on applications over the network are invariably going to break at some point. #1 on the “Fallacies of distributed computing”:
The network is reliable.
This is usually applied over local networks between applications like Redis, MySQL and other supporting services, but the risk of failure in a network (approximately) increases by the number of network hops.
Third party services definitely land in the “high risk” pile. There’s often 10–15 network hops between them, and even when those networks are stable the third party service can fail for ${REASONS}.
In Conclusion
System fail in interesting and unpredictable ways. But given enough failures, patterns start to emerge around those failures, and it’s possible to build systems into code such as early termination, graceful failure handling and retries that make an invariably unreliable system more reliable.
Thanks
Sitewards. It’s nice that I can write this stuff up — not everyone gets to.
My team. ❤