
Case Study: Architecting a system with “infrastructure as code”
Our collaboration with Schramm Werkstätten restructuring their production system on Amazon Web Services with Ansible


Our collaboration with Schramm Werkstätten restructuring their production system on Amazon Web Services with Ansible
On August 25th, 2005 the eCommerce giant “Amazon” released their virtualized compute service “Elastic Compute Cloud” (EC2). What would follow is among the largest shifts in web technology in history, and signalled a fundamental shift in the business model of Amazon toward specialising in cloud computing under “Amazon Web Services” (AWS).

This new model of cheap, virtualized compute fundamentally changed how we think about the “hosting” component of the application. No longer was it required to have a specialised team to rack, stack and maintain a set of servers — they were trivially available and moments away via AWS.
This new model of compute came with a set of opportunities:
Applications that could scale quickly
Trivial disaster recovery
Trivial deployment of new applications
But though AWS solved the racking and stacking of servers, it did not solve the maintenance problem. It did, however, allow software developers to treat the underlying compute as software; to program it as if it were any other set of programmatic APIs.
Infrastructure as Code
With the rise of infrastructure that could be treated as software a whole new set of tools and services were released or given new life to take advantage of this new capability:
Configuration Management: Ansible, Chef, Puppet
Monitoring: Prometheus, InfluxDB, StatsD + Graphite
Log Aggregation: systemd-journald, ELK stack, Graylog
Systems Introspection: OSQuery, Sysdig
Systems Integrity: OSQuery, Falco
Theses tools take the notion of a Linux server and return an abstraction that makes those servers easy to reason about. For example, in the case of Ansible instead of:
$ sudo apt-get install php7.2-fpmThey instead allow:
- name: Ensure PHP packages are installed.
apt:
name: "{{ php_packages }}"
state: "{{ php_packages_state }}"
install_recommends: "{{ php_install_recommends }}"
register: php_package_install
notify: restart webserverWhile the later version is longer, it means that once Ansible has been run on that machine it is guaranteed to have PHP installed. Additionally, Ansible will continue to make sure this is true every time this it is run.
Practically this means the server is in a reliable state 100% of the time and the servers current state is reflected in version control, which is kept for the lifetime of the project. This dramatically reduces the investigation time required before any change, and increases the safety and testability of those changes.
Lastly, by encoding the infrastructure in code this code can be shared and reused across many different systems, dramatically reducing the cost of designing each of these systems. Definitions are even shared as open source software and organisations partner together to develop definitions that maximise safety and security of the infrastructure while driving down the cost of designing this infrastructure to negligible levels.
Designing Schramm Werkstätten

Schramm Werkstätten (Schramm) are a manufacturer of premium bedding and other house furnishings that sells via distributors to consumers and directly to the hotel industry. Their furnishings are a uniquely premium product best suited for particularly discerning buyers who value quality above all else. With this context, the store was designed to convey a similar impression of quality.
Additionally, in the past Schramm had difficulty ensuring their system remained their own during times of dispute with other third parties and were thus particularly keen to ensure that they were in control of their own infrastructure in the case that relations with Sitewards become similarly difficult in future. Though I’m happy to write this has not been the case so far, we understood their desire for sovereignty over their own systems and data.
As a compromise between systems that we could work with and systems that would remain in the absolute control of Schramm we elected to design their system on top of EC2 in AWS.
We began the implementation on June 21st, 2017.
The general design
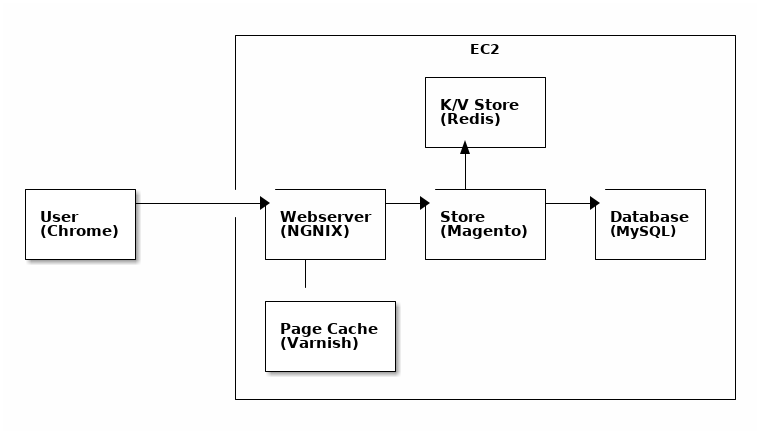
The store was a fairly straightforward “Magento 2” type infrastructure whose requirements were well known to the team at the time of implementation. However, this would be our first time being as ambitious with our infrastructure as code designs.
Specifically we set the following requirements:
The entire infrastructure needed to be specified with Ansible
The infrastructure needed to be replicable exactly in testing environments
The application changes should be managed in their entirety by Ansible
Invocation of Ansible should be automated by BitBucket Pipelines
This had to be completed for at least two environments:
Testing: An environment used to verify changes before production
Production: A user-facing environment
Work fairly rapidly processed and the first deployments for showrooms were happening approximately 2 weeks following. The release process works approximately as follows:

The developer will trigger the “Pipeline” or deployment process through the BitBucket UI
The pipeline runs Ansible, the tool for managing the infrastructure as code, with the appropriate configuration
Ansible updates the testing or production server, deploying the appropriate changes as required.
The first deployment to production was approximately 4 weeks later:

The pipeline is now the only way that all deployments happen to both testing and production systems, having been run approx 1400 times at the time of writing over a two year period.
Return on investment
Implementing an infrastructure as code approach increased the initial investment for the project but has long since paid for itself many times over. There were a variety of ways in which this approach made the project much cheaper and simpler to maintain than alternatives:
Project Ownership
To address the primary impetus for this design the project must remain in the control of Schramm at all times, but administered by the team here at Sitewards.
Using AWS allows this as the team has been granted the appropriate user rights to access the machine, however revocation can be implemented at any time and instantly by undertaking the following steps:
Revoking all developer IAM keys provisioned in the AWS account
Revoking the firewall rule exception allowing us access to the servers themselves
Because all of the infrastructure was created through this infrastructure as code approach Schramm have access to all material needed to recreate all aspects of the system (through their version control access) with detailed changelogs as to when each change was introduced and why.
Automated Deployments
In our experience the primary cause of user facing issuers is when developers change the software in some way. This is a catch 22:
Software that does not change is stable
Software that does not change can become unsafe over time
Software that does not change does not increase business value
Historically this was approached by developing the software for some period of time after which it would be submitted to a quality assurance process. That process would hopefully shake out enough of the bugs for repair that the software would be usable by users, after which it would be released. This is generally referred to as the “Waterfall” model, and is best demonstrated by the regular releases of the “Microsoft Office” suite.
The problem with this approach is that the software is essentially designed in a vacuum, without user validation. This results in exceedingly large software investments that can turn out to be catastrophic failures; one famous example being the English NHS “connecting for health” which despite a 12 billion Dollar investment was ultimately scrapped.
To address this we try and ensure that changes are pushed out to users as quickly as possible so that we can learn from those users whether what we’ve hypothesized to be the case is actually true.
However this directly conflicts with our previous desire to keep software stable.
To drive down the risk of change we break down deployments as much as possible until only single features or changes are deployed at any one time and can be easily reverted, and that the actual act of deployment is essentially a zero-risk operation.
To do this we need to control nearly all aspects of the infrastructure, only possible by taking an infrastructure as code approach. This approach allows us to identify and factor in any risks associated with the process of getting code in front of users until those risks are essentially negligible, after which code can be freely shipped.
In the case of Schramm, at the time of writing there have been ~1400 deployments in two years. Given the 48 working weeks of the year that means approximately 14.5 tests per week, of which only a small percentage actually end up in front of users after being validated by other project stakeholders. The changes can then be easily sent to the production system, and should those changes not perform as expected, just as easily removed.
Additionally and in terms of a purely financial evaluation, prior to automation each deployment took a minimum of ~30 minutes. Over the two years, approximately 700 hours of deployments were automated, or 90 days of “developer time”. That 90 days was instead spent on improving the service for users, or simply not spent at all.
Performance

The system was initially designed and has been subsequently improved to have exceptional performance in a number of dimensions:
DNS is hosted on Route53; a globally distributed, highly available DNS
TCP and TLS connections were optimized by enabling newer TLS features
Minimal server processing time is required to load cached content
Transfer is out of the AWS Frankfurt data centre, close to Schramms user’s
Even from a “cold start”, or on the first page visit the server responds in a reasonably quick 203ms:

By using an infrastructure as code approach we were even able to automatically optimize the site based on the device that was accessing the site through “client hints”, or based on the screen size of that device.
Specifically, for all image requests images are processed through an additional server called “Thumbor” which optimizes the image as much as possible for all devices, but where it knows the size of the device that is accessing the site, further reduces the size of the image without noticeable loss to the users.
With Schramm being a heavily visually driven site the difference was approximately 21%, or 1.9MB (Pixel 2) vs 2.4MB (Desktop).
Reasonability
Naively, it’s easy to consider developers spend their time making amendments to the software to make it do new and interesting things. However, software is generally of such complexity that it cannot be easily changed without first understanding the surrounding environment. Indeed, the majority of development time is not spent writing code, but rather reading it and trying to understand it.
Via Twitter:
Robert C. Martin, one of the proponents of the Agile movement elaborates on this further:
“Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. …[Therefore,] making it easy to read makes it easier to write.”
In the absence of any code to read, developers must do an extensive investigation of a system before they change it. This investigation follows the following workflow:
Based on experience, determine a hypothesis
Test that hypothesis
Repeat
That process has some significant drawbacks:
It eats expensive development time
It relies on the experience of the software developer
The knowledge gained is rarely documented in any useful fashion
Infrastructure as code sidesteps that entire set of issues by encoding all the information up front as an infrastructure definition.
This dramatically reduces the cost associated with investigating the class of bugs associated with the “infrastructure” — all things outside the application. Specifically:
Encoding it in a definition allows development teams to describe how and why they change things
The definitions themselves are a domain language designed for the purpose, and dramatically cut down the cost of understanding.
This translates to fewer bugs in the infrastructure definitions and when those bugs do occur, much smaller times to investigate and resolve those bugs — a much cheaper system over time.
In the case of Schramm, the infrastructure as code has been modified over time for the features:
HTTP/2
Thumbor
Falco
OSQuery
PHP 7
Developer Access
CN Release
URL Restructuring
All either much more expensive or impossible without the infrastructure as code definition.
Introspectability
In addition to the class of problems associated with defects in the code, there are a class of problems that are characterized by unanticipated behaviour in the production environment. This includes things like:
Third party services not being available
More users than anticipated consuming the service
Scheduled jobs running with user actions competing for system resources
Users consuming the service in unexpected ways
Users actively abusing the service
These problems are inherently difficult to predict. While we take patience to implement things to make it significantly more difficult for users to abuse our services, users are creative and the ways services are being abused are always changing.
At the time of writing on a single system and via a single service (SSH), there were 2546+ attempts to “hack” (via brute force) the system in the last 24 hour period.
Whether users are actively abusing the system or whether some properties of the system are simply behaving in ways that we did not anticipate, we need to be able to verify how the system is actually behaving versus how we think the system should behave.
Being in control of the infrastructure and adopting an infrastructure as code approach allows us to preemptively “instrument” the system. Then, when later disasters do invariably happen we can clearly see when and why they happened and put steps in place to prevent their recurrence.
In the case of Schramm we added:
Prometheus (NGINX, Redis, Varnish, Node, MySQL)
Logging all process logs to systemd-journald
OSQuery to query machine state and verify changes over time
Sysdig / Falco to verify machine behaviour
Practically speaking this service has been almost problem free; there are minor issues that have been surfaced via Prometheus, and logging has helped track down some particularly difficult application bugs. OSQuery is essentially unused and Falco highlighted some odd, but ultimately harmless application behaviour.
The nature of this instrumentation is that it is not useful until a problem has been reported, after which the instrumentation can be used to retroactively analyse a problem. However the instrumentation gives us the confidence that the machine is and has been operating correctly for months at a time, and that there has been no successful user abuse.
Redundancy
Because the compute on AWS is virtualized, the underlying storage that the compute needs to use is also virtualized. Using this storage has some unique guarantees as compared to physical hardware, or less well tooled hosting providers:
Backups are essentially instant and trivially recoverable via “Snapshots” of the disk.
The disks can quickly and easily be resized if space becomes low
A copy of the production instance can be recreated from a time period before to compare
By comparison, other third party systems can take up to weeks to perform the same recovery procedures.
This decreases the risk associated with system change. That decreased risk translates into the ability to undertake relatively higher risk changes, significantly increasing development velocity.
Lessons Learned
Schramm was our first project that used infrastructure as code to automate all aspects of the system. Since then we’ve moved the majority of our projects to follow a similar design, all of which have benefited in similar ways from the Schramm prototype.
Reusability
The initial Schramm design was highly influenced by sets of code reused from the previous work by Jeff Geeling, Julian (Juju4) and others. We designed our own code following the patterns of those who had released their code before us, and have subsequently released much of the code on GitHub:
Sitewards
Sitewards has 22 repositories available. Follow their code on GitHub.github.com
We reuse much of the learning from the Schramm project across other projects, further cutting the cost of those projects and maximising the returns for all involved as bugs are found in those projects and the fixes contributed back.
Pipelines
Much of our deployment process is now run by a CI/CD process in the “Bitbucket Pipelines” product. While this would not be possible without first defining the infrastructure as code it maximizes the returns possible with this sort of infrastructure, encoding any further knowledge required to run the system in procedural scripts known as “pipelines”.
Production First
In the Schramm project the goal was to make the case that we were suitably equipped to not only handle the testing environments, but also the production environment. Accordingly production was a first class component of all aspects of the design; something that hadn’t been tried before.
This paid off significantly as production and testing systems are almost identical, greatly reducing the risk that an issue will make it to the production system without first being found in QA and reducing the amount of “acceptable discrepancy” between the testing environments and the production environment.
Container Driven
While the technology around virtualized compute had some dramatic improvements to the economics of this side of service development, containers offer even further possibilities.
Containers shift the paradigm from having a production system that must be maintained to building and releasing production systems as a single, immutable unit. This was possible with virtualized machines but cost prohibitive and slow.
Orchestration tools such as Kubernetes provide better models to describe multi-service systems, as well as ways to colocate processes on a smaller number of machines maximising the amount of compute available at a smaller price point.
In Conclusion
Infrastructure is one critical part of managing a service such as Schramm Werkstäetten. Historically this was managed by third parties, but Sitewards was able to break away with the help of tooling designed for infrastructure as code to develop systems of equal or superior quality to those third parties. This allowed an architecture and design by Sitewards, tailored to each project partner.
The initial investment in infrastructure as code has netted significant cost reductions for the Schramm project and will continue to do so, with those savings far outweighing the initial invest.
Further, designing systems in this way allows the development team to iterate faster and with less risk allowing a management style that is fundamentally faster and better driven by market demand.
Infrastructure as code is one component of a successful project. To understand how this would fit into your project, get in touch with the team!
Thanks
Antonius Koch, Nils Woye for their review.